Identifying sessions consuming CPU time is a common task in Oracle performance tuning. However, as simple as it sounds, it is not that straightforward. Oracle recommends using Enterprise Manager or Automatic Workload Repository for that. The problem is that in real-life situations Enterprise Manager is often not installed, or you may not have access to it. You may not also have necessary privileges to run AWS. Besides, running AWS reports for such a simple task sounds like overkill.
Oracle database reports each session’s CPU usage in V$SYSSTAT performance view. However, it only indicates a total CPU time used since the session’s log in. And because different sessions may have logged in at different times, you can’t compare the reported figures as they are. After all, it is obvious that a session logged in a few days ago cumulatively may have used more CPU time than a session started just a few minutes ago.
However, there is a workaround.
I wrote a script which accurately measures CPU time consumed by Oracle sessions within the given period (30 seconds by default). It works by taking a snapshot of CPU stats at the beginning of the interval, and then another one at the end. It then calculates the CPU time used during the interval and presents the sorted list.
It prints the result into dbms_output in the following CSV format:
sid, serial#, cpu_seconds
Once you identified the top CPU consuming sessions, you can use a script like this one to find out what they are doing.
You can download cpu_usage.sql script from my GitHub page.
Here is a small script which shows information about running Oracle sessions. You can use commented lines to filter by an Oracle instance (in case you have a RAC), OS user, session ID, process ID or an application name.
This is a spinoff of Obsidian colour scheme for Oracle SQL Developer. It is based on Obsidian Eclipse colour scheme by Morinar.
Unfortunately Oracle doesn’t make it easy to import a new colour scheme into SQL Developer, thus a little bit of hacking is required.
-
Close SQL Developer. This is important. If you modify the scheme file while SQL Developer is open, your changes won’t be saved.
-
Locate file dtcache.xml in the SQL Developer’s settings directory. On my system it is located in directory C:\Users\sergey\AppData\Roaming\SQL Developer\system4.0.3.16.84\o.ide.12.1.3.2.41.140908.1359
-
Locate <schemeMap> tag inside dtcache.xml file. Insert the content of ozbsidian-scheme.xml file inside <schemeMap> alongside the other colour schemes. Be careful not to break the XML.
-
Launch SQL Developer. Navigate to menu Tools->Preferences, then select item Code Editor -> PL/SQL Syntax Colours in the left pane.
-
Select “OzBsidian” in the “Scheme” drop down list on the top.
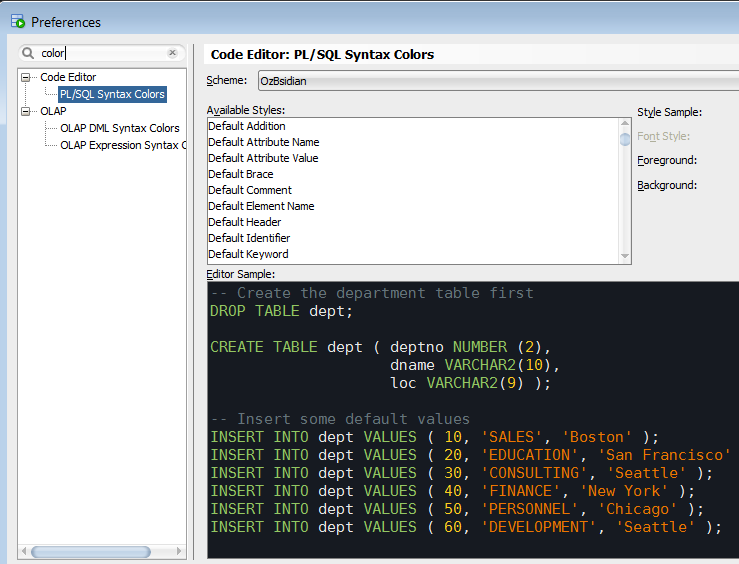
The colours are mostly match Obsidian scheme, although not exactly. For instance, the background is a bit darker. Hence the name is OzBsidian to differentiate it from the original scheme.
You can download the colour scheme with the installation instruction from my GitHub account.
Enjoy!
If you ever wanted to know how what’s taking space in an Oracle database, or how large is the table you’re working on, here’s a script which answers these questions. It shows the size of all the database objects large than 10 Mb in a particular database schema.
The following columns are returned:
- Owner schema.
- Object name and type (INDEX, TABLE, etc.).
- Name of the table this object is associated with. E.g. indexes are associated with their parent tables.
- Database space occupied by the object in megabytes.
- Tablespace this object is in.
- Number of extents allocated for the object.
- Size of the initial extent in bytes.
- Total database size occupied by the parent table. E.g. for indexes it will be the size of the parent * table plus sizes of all the indexes on that table.
This script is based on the Stackoverflow.com discussion.
As I have already shown you, implicit type conversion is one of the most dangerous features of Oracle SQL and PL/SQL. It is dangerous because it happens automatically without your knowledge and may lead to unpredictable results. These problems are most common when dealing with DATE conversions, but not limited to them.
For example, let’s have a look at this Stackoverflow.com
question by James
Collins.
James had a problem, the following query was slow:
SELECT a1.*
FROM people a1
WHERE a1.ID LIKE '119%'
AND ROWNUM < 5
Despite column A1.ID was indexed, the index wasn’t used and
the explain plan looked like this:
SELECT STATEMENT ALL_ROWS
Cost: 67 Bytes: 2,592 Cardinality: 4 2 COUNT STOPKEY 1 TABLE ACCESS FULL TABLE people
Cost: 67 Bytes: 3,240 Cardinality: 5
James was wondering why.
Well, the key to the issue lies, as it often happens with Oracle, in
an implicit data type conversion. Because Oracle is capable to perform
automatic data conversions in certain cases, it sometimes does that
without you knowing. And as a result, performance may suffer or code
may behave not exactly like you expect.
In our case that happened because ID column was NUMBER.
You see, LIKE pattern-matching condition expects to see character
types as both left-hand and right-hand operands. When it encounters a
NUMBER, it implicitly converts it to VARCHAR2. Hence, that query was basically silently rewritten to this:
SELECT a1.*
FROM people a1
WHERE To_Char(a1.ID) LIKE '119%'
AND ROWNUM < 5
That was bad for 2 reasons:
- The conversion was executed for every row, which was slow;
- Because of a function (though implicit) in a
WHERE
predicate, Oracle was unable to use the index on A1.ID column.
If you came across a problem like that, there is a number of
ways to resolve it. Some of the possible options are:
- Create a function-based index on
A1.ID column:
CREATE INDEX people_idx5 ON people (To_char(ID));
- If you need to match records on first 3 characters of
ID
column, create another column of type NUMBER containing just these 3
characters and use a plain = operator on it.
- Create a separate column
ID_CHAR of type VARCHAR2 and fill it with
TO_CHAR(id). Then index it and use instead of ID in your WHERE
condition.
- Or, as David Aldridge
pointed out: “It might also be possible to rewrite
the predicate as
ID BETWEEN 1190000 and 1199999, if the values are
all of the same order of magnitude. Or if they’re not then ID = 119 OR ID BETWEEN 1190 AND 1199, etc.”
Of course if you choose to create an additional column
based on existing ID column, you need to keep those 2 synchronized.
You can do that in batch as a single UPDATE, or in an ON-UPDATE trigger,
or add that column to the appropriate INSERT and UPDATE statements in
your code.
James choose to create a function-based index and it worked like a charm.