Some time ago I wrote
my thoughts on the modern state of PC music-making applications.
In the nutshell, I reckon that niche became too overpriced and
overcomplicated. All the existing digital audio workstations are
targeted towards professional users, with the price tags to match. At
the same time, the area of casual music production remains a no-man’s
land.
Since then I got an iPad and discovered that simple and cheap music apps
which I missed so much are plentiful there. I am excited about the
emerging phenomenon of music production on iOS. There are already
all-in-one DAWs for iOS such as
NanoStudio and
BeatMaker2, and even
multitrack recording DAWs such as
Auria. Moreover, while virtual
synths for PCs & Macs cost circa $100 or more on average, synths of
comparable quality for iOS are about 5 times cheaper. If you doubt, take
a look at AniMoog,
WaveGenerator, or
nLogSynth.
Since its appearance the iOS music scene is expanding rapidly. Large
companies start to realize that iPad is not just a toy, and the recent
inflow of software from Korg,
Moog,
Akai, and the most recent,
Steinberg
and
Yamaha
is the proof of that.
Indeed, I reckon we are witnessing a rise of a new music making
platform. The platform which is simple and accessible enough for
beginners yet has a potential to become powerful enough for
professionals.
A few days ago I installed Oracle Linux in an Oracle VirtualBox VM. Once it was installed I found that eth0 interface wasn’t starting upon boot.
That was unusual. I am myself a Linux enthusiast, and I regularly download and install lots of distributions, and, by and large, network works in them out of the box.
Today I finally got around to troubleshooting this problem. It took me a couple of hours digging through the scripts, setting trace points, and reading logs; and here’s what I found.
For the reference, this was my configuration:
Oracle VM VirtualBox 4.1.22 r80657
Host: Windows 7 64-bit
Linux: Oracle Linux Server release 6.3
Kernel 2.6.39-200.24.1.el6uek.x86_64 on x86_64
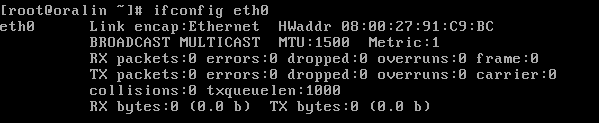
As I said, upon boot eth0 was down. If I tried to bring it up with ifconfig eth0 up it came up in IPV6 mode only, no IPV4:
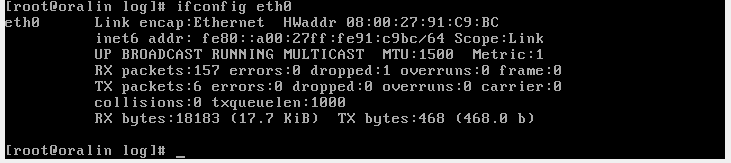
Hm, weird. What was even more weird was that if I brought it up with ifup eth0 instead of ifconfig eth0 up, IPV4 network started succesfully:
Obviously, these 2 were are different. The reason ifup worked was because it called dhclient to obtain an IP address from a DHCP server
Whereas ifconfig didn’t make that call. And because the network interface did not have an IP address, it stayed down.
So, what is the difference between ifup and ifconfig up?
Well, ifup is actually a script located in /etc/sysconfig/network-scripts.
During the system boot the network subsystem is brought up via startup
script /etc/rc2.d/S10network. That script goes through all the network interfaces it can find and
brings them up during the boot. What’s interesting, I found that it uses a set of configuration files
/etc/sysconfig/network-scripts/ifcfg-*<interface_name></interface_name>* to determine if a particular interface needs to be brought up during the boot time. There is one config file for each interface. I’m not sure
when they are created, maybe at install time.
In my case I found that one of the parameters in ifcfg-eth0 file was ONBOOT=no.
Turned out the network startup script uses that parameter to determine if the particular interface should be brought up at the boot time.
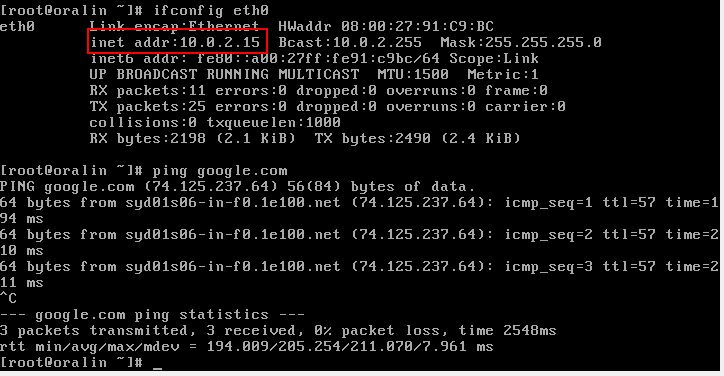
So, I changed it to ONBOOT=yes and everything worked.
Now when the system starts, eth0 is up and running.
Problem solved!
Update:
So, the mystery is finally solved. There is “Connect automatically” checkbox on the installer’s network configuration screen (item 10 here).
If this checkbox is unchecked, network interfaces do not come up at system start-up.
Many thanks to the Oracle Linix team for helping me in this investigation.
All database applications can be divided into 2 classes: OLTP and data
warehouses. OLTP stands for Online Transactions Processing. It’s easy to explain
the difference between them by an example.
Imagine yourself buying groceries at your local supermarket. When you
are done filling your shopping basket and finally come to checkout,
here’s what happens:
A shopping assistant at the checkout register picks up your first
item and scans its barcode. The computer built into the register
turns the barcode into a series of characters and digits and queries
the store’s database for the item’s description, price and picture.
Then it adds the item into your virtual shopping cart.
You reach for your next item and all of those steps happen again: a
few queries sent to the database, a few tables updated. And then
again and again, until your basket is empty.
You swipe your credit card. The shop’s system sends a request to the
credit card processing centre. It checks that you card is valid and
that you are not over your credit limit. Then it asks you for your
pin code, verifies it, and if all the checks are successful,
withdraws the money.
Then the groceries you bought are marked as sold in the inventory
control system. A receipt is printed, and the virtual shopping
basket is cleared. That’s it. Thank you for shopping with us.
It probably took you less than 5 minutes to go through the register. But
the number of database queries and updates it resulted in was likely in
hundreds. Now multiply that by the number of checkout registers in the
shop, and you’ll get the picture. Checkout register is a typical OLTP
system.
OLTP applications are characterized by large volume of atomic database
transactions: retrieve 1 row from a database table here, 3 there, insert
a few lines into a third table or update a row of yet another table.
Most of OLTP-type applications are interactive: you press a button and
expect the system to respond within a few seconds at most. That presents
a challenge if the application is a multi-user system with hundreds of
users working at the same time. It is not uncommon for an OLTP system to
crunch tens of thousands, even millions of database operations per
minute. And because of that these operations need to be extremely fast.
Therefore OLTP systems are specifically engineered for a low latency in
conditions of high volume of elementary database operations.
Now imagine that at the end of the financial year the COO of the
supermarket chain requires a detailed sales report. He wants to know
which products were selling faster comparing to the previous 10 years
with a breakdown by geographical areas. He also wants to know the
correlation between the increased prices and sales volumes aggregated by
product categories, and so on. Every business requires hundreds and
hundreds of such reports, and not just at the end of the financial year
but sometimes every day. Financial departments, sales, marketing, and
management – they all want to know how the business is doing. In fact,
there is a special buzzword for that kind of reporting – “Business
Intelligence”. Another buzzword “Data mining” means “Looking for answers
for which we don’t know questions yet”. Data mining looks for trends
within the data and tries to find correlations to the known parameters.
An example of a data mining query is “Find out if the sales volume
changed within the last year and what else is changed that could explain
that”.
Business Intelligence and Data Mining reports tend to be highly complex.
Most of times they require querying data across very large datasets,
such as all sales over the last 10 years, then aggregating it, then
calculating summaries, averages, correlations and so on. These are very
different types of operations from which OLTP systems are designed for.
And that is why running them against OLTP databases is usually not a
good idea. This is what data warehouses are for.
Data warehouses are database systems optimised for complex database
queries over large data sets. They are predominantly used for Business
Intelligence and Data Mining reporting. Within large corporate data
warehouses it is common to have “sections” designed for specific
purpose, for example for particular types of financial reports. These
sections along with their business intelligence logic are called
Datamarts.
Data warehouses usually source data from multiple systems. For example,
sales data, financial data, inventory, vendors, etc. may come from
different geographically distributed platforms which otherwise don’t
talk to each other. Having all this information in one data warehouse
enables business users to get reports such as profits on sales of
certain goods per supplier.
The Composing and Producing Electronic Music course is finally over. I learned a lot over the past 12 weeks on topics like sound design,
harmony, song composition and sound mixing. It was a great experience.
However, this is what concerns me.
I found that making music is:
Terribly expensive
Terribly unproductive
It may make perfect sense for someone aiming to make professional
recordings. But what about someone for whom it is just a hobby? It looks
like we can’t even start doing anything without spending hundreds and
hundreds of dollars on MIDI controllers, DAWs and plugins. All that
stuff is expensive and it looks like there is no other option.
In 1997 when I started playing with digital audio, I had a Yamaha sound
card that had few hundreds instrument samples in it and a software that
allowed me to tweak the parameters of every single one of them. I paid
$200 for it. It had samples of real pianos, guitars, organs, you name
it, as well as built-in subtractive and FM synthesizers.
If I want to get anything like that now, what are my options? $500 NI
Komplete? If anything, in these 15 years it got more expensive. For one
of my projects I needed a sound of a steel guitar. I discovered that it
was not easy to get. Kontakt is awesome but it is expensive. It comes
with 50 Gb of samples. I wanted something that had a couple of hundreds
multisampled instruments in maybe 5-6 Gb for the quarter of that price.
And I couldn’t find it. That choice had to be available 10 years ago,
now it just disappeared.
Is there an option to even start doing good music on the cheap?
Then comes complexity. It is uncommon for an EDM artist to spend
hundreds of hours on a 5-minute song. On something that will be enjoyed
for 5 minutes. Of all the arts this must be one of the most
unproductive. During the course we learned to program drums, write bass
lines, layer, synths, etc. What looks odd to me that for each new song
we have to do all that from the scratch – we need to put all these tiny
little pieces together bit by bit. There seem to be no way to reuse, to
build on top of what’s already done. Again, this may be fine for someone
doing EDM full time. But if I have a couple of hours here and there, it
looks like I need to give up without even trying.
There are some entry-level DAWs such as Garage Band and Cubase LE. But
my impression is they are just stripped-down versions of the
fully-functional DAWS. They don’t make anything easier. If anything,
they actually make music making harder because they maintain the same
attitude as the fully-functional DAWs but remove critical pieces of
functionality. What’s the point paying $100 less for a DAW that is not
capable of running VSTs? That is not a kind of “simplification” I’d like
to get. And all the modern fully-functional DAWs grew into multi-headed
hydras. Compare Cakewalk 10 years ago and now. I know some people who
tried to do anything in Ableton Live and immediately felt intimidated by
its complexity.
I don’t like where it is all going. I reckon that electronic music will
benefit by bringing more people into it, by making producing EDM more
accessible. Everyone can be an artist, but not everyone needs to be a
professional artist. However, I see exactly the opposite. Computers
became cheaper and more accessible, but over the last 10 years the
complexity and cost of making electronic music skyrocketed. And I don’t
think that is right.
If tomorrow one of my friends wants to get into EDM and asks me how,
what should I say: “Don’t bother. If you are not prepared to spend big
bucks, then leave your job and make music full time, it’s not even worth
trying?” It is ridiculous. But is looks like that because all the
software and the process that software enforces are tailored for
professional producers.
Nonetheless, it doesn’t have to be like that.
Let’s take photography. It used to be complex to make photos. Now
everyone can do it. Professinal use Photoshop for photos processing. And
it suits them. I’m not a professional and I use Picasa. Instead of
hundreds of sliders like in Photoshop, Picasa has button “adjust photo
automatically”. Which works for me 90% of times.
Now, if I want to make music, I have no alternative but to use a DAW
equivalent of Photoshop with all its cost and complexity. Why my DAW
doesn’t have “make sound awesome” button? You say it’s impossible? I
don’t think so. For example, professional mastering plugin iZotope Ozone
retails for $250 in its basic configuration. Although it has tens of
sliders and knobs, a pretty common way to use it is to start with a
preset and then made tiny adjustments. So why not make it simpler - drop
all the knobs and sliders and leave just 20 presets. Then sell in for
the quarter of the price. It will make it accessible to a lot more
people, and will be enough for 80% of them. Making something simple does
not mean making it less sophisticated. Think iPhone. It is a masterpiece
of sophistication in a beautifully simple form.
I think a current state of music making art is wrong, and it is due for
a change. Everyone should be able to make music. And all the software
should make it more accessible to everyone, not just for a bunch of
professional music producers. The message that should be out there is
that making music is simple, and it is fun. But at the moment it is
neither of those.
I don’t know why. Maybe because software companies just aren’t
interested. Maybe it is beneficial for them in some way to create an
aura of music making as something accessible only to chosen ones. It is
wrong. It needs to change.
Who knows, may be one day it will be my job to change that. Everything
is possible in this world.