It is a scientific fact that the amount of entropy in the universe
increases all the time. One day it may break the hell lose on our world,
leading to a new Big Bang.
Entropy is the Engine of Chaos, and this is its song of destruction.
First of all, I found that I am not good at playing drums. After I
“played” it I had to heavily edit it in the piano roll to match the
groove. Next time when I do my own complex groove from scratch, it will
make sense for me to draw the groove on paper first, then play it and
edit.
Here’s the 100% quantized groove:
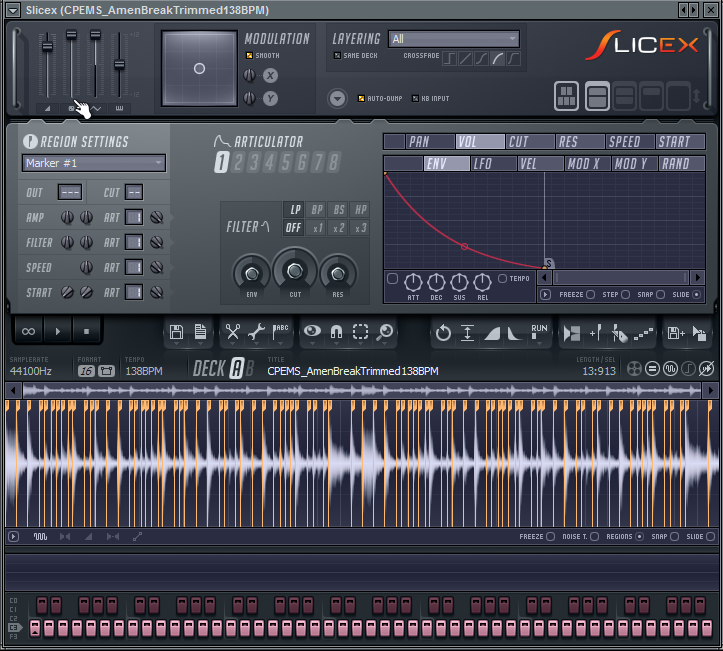
Then I dropped the original Amen Break groove into Slicex, which
automatically sliced it. Oops, made a mistake here: before slicing the
loop should have re-detected it tempo or manually set it to 138.
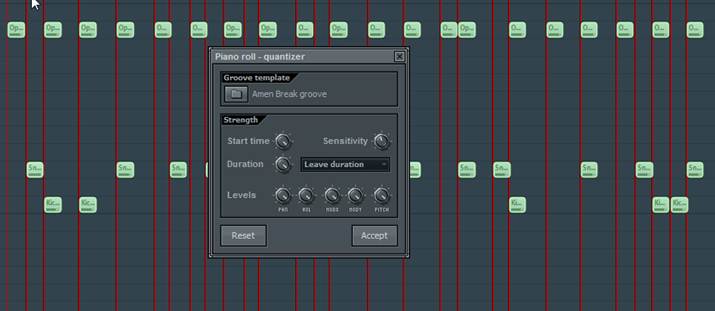
Then dumped into piano roll as groove template.
After that I quantized my drum’s piano roll based on the groove template:
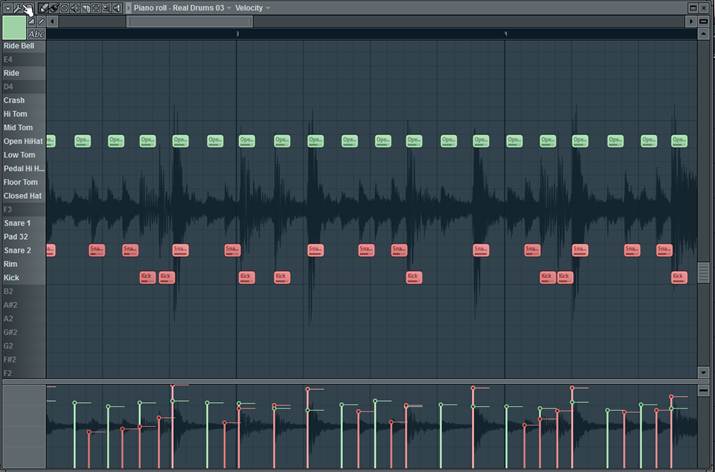
And here’s the final Amen Break in MIDI:
You can see the waveform of the original Amen Break in the background.
It is helpful for matching velocities.
The drums sounded ok, but I wasn’t satisfied with the riding cymbals. It
seemed like somebody was kicking the bottom of the can. I ripped them
off this midi track. Then I found the cymbal sound I liked in my library
and recreated the cymbals using the Step Sequencer.
Then applied 50% swing:
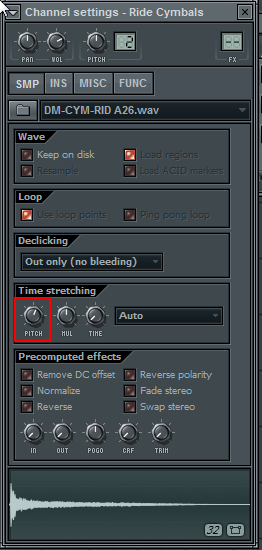
I also adjusted the cymbal’s pitch to match the original Amen Break:
Then I added an orchestral hit into the same step sequencer. And again, adjusted its pitch.
Here’s final Amen Break in MIDI:
Just to add a little variety I found a DnB an appropriate drum kit in
Drumaxx
and used it for the drums track. Then I laid the sub kick I did in
Massive over it. Audio editing is frustrating in FL, so to the limited
available time I decided to do away with it this time.
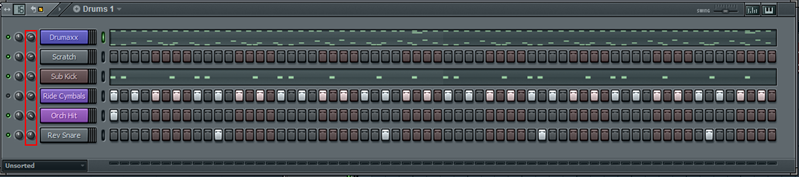
As for mixing, I assigned all the drums to the same mixer track and used
the level knobs on the pattern tracks to adjust relative volumes of the
tracks:
As far as I can see, FL does not have a concept of a mixer bus. Instead
output of each mixer track can be directed to an input of one or more of
other mixer tracks. And vice versa, any track can take input from
multiple other tracks (hence serve as a submix track).
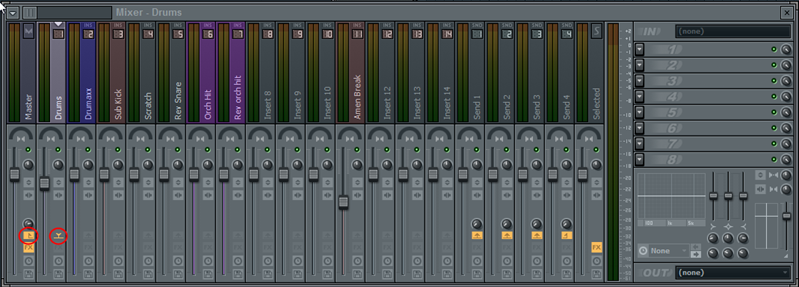
In the screenshot below I created a “Drums” track (1) to serve as a submix of all the drums tracks (2-7).
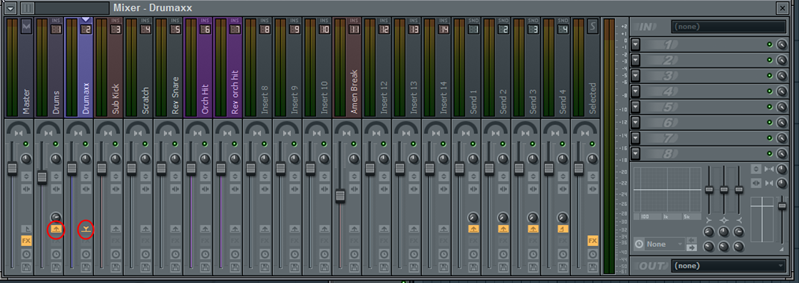
The circled pictograms on the screenshot above indicate that the output
of Dummaxx track 2 is directed to the input of Drums track 1. And the
output of “Drums” track is routed to Master:
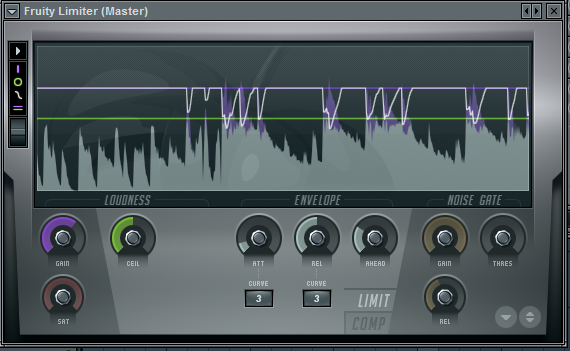
FL puts a limiter into the master track by default, and I left it there
with the default settings. As a result, the drums sound compressed but I
reckon it’s actually better that way.
Here’s the end result:
That’s all for this assignment. If I had more time, I would program 1 or
more different drum patterns a switched them after 8 or 16 bars.
Databases are at the core of virtually all modern information
technology systems. Sometimes these databases are exposed, for
example, as in data warehouse systems. The centrepiece of a system
like that is a powerful industrial database such as Oracle, or
Sybase, or Microsoft SQL Server, or something similar. The presence
of a database is pretty obvious in that case – only these powerful
databases can crunch the immense amounts of data processed by data
warehouses. In other cases databases are hidden. For example, Apple
iTunes uses a SQLite database to store the details of music tracks on
your computer. That database is not obvious; it does not advertise
itself, but it’s there. It makes sure that the ratings you assigned
to songs are saved and can be synchronised between all your iPhones
and iPads. It counts the number of times every song was played so
that you don’t listen to the same song twice when you put your iPhone
on shuffle. Databases are everywhere. They all serve the same purpose
– to store data and make its retrieval as easy and fast as possible
– but they are also vastly different from each other.
Let’s take another example. When you log into your Google account
and bring up your Gmail inbox, all the emails you see are actually
stored in the remote database. That database is called BigTable, and
it contains not only your emails, but all the emails of all Gmail
users in the world, and also virtually all of Google’s data. While
your iTunes SQLite database may be about 50 megabytes in size (and
that’s assuming you have A LOT of songs), Google’s BigTable contains
petabytes of data. That’s your iTunes database times one billion.
If you think about it, it becomes obvious that these databases
require vastly different approaches to the way the data are stored
and retrieved: You can fit an iTunes database into memory and query
it whichever way you like without a performance penalty. At the same
time, no machine has been built yet that could apply the same
approach to Google’s BigTable.
Unfortunately, not all software developers understand that.
Databases once were an inspiring topic but in recent years they went
out of fashion. Software developers are geeks; they like new toys;
they all want to work on something latest and greatest and
cutting-edge. So many new exciting things are happening in the area
of Information Technology – Web 2.0, HTML5 and Apple iOS to name
just a few – that databases just fade in comparison, despite the
fact that they make all these new shiny things tick. Most of the
developers these days take a database just as generic data storage:
“We’ll just stuff the data in and we don’t care what’s inside.”
10 years ago SQL language was a necessary skill for database
application developers. Nowadays the majority of programmers don’t
know SQL. They rely on frameworks such as Hibernate to produce SQL
statements for them. They think that all databases are the same and
therefore, if necessary, they can take one system that uses MS SQL
Server as a backend and put it onto Oracle and it will work just
fine.
Well, that may be true for very simple applications. The myth that
all databases are the same is flawed, especially when it comes down
to performance. Today cloud computing is a buzzword, and Google is
the patriarch of the cloud. Google’s servers process billions of
requests every day, crunching petabytes of data. Yet, every request
made to a Google search engine is served within seconds. This places
such a high demand on the Google’s database layer, that Google’s
engineers couldn’t afford using even the most powerful of industrial
databases, and they had to develop their own – the aforementioned
BigTable. If you told these guys that “all databases are the same”,
they would laugh into your face, and rightfully so, because Google
knows that performance matters and they try to squeeze every bit of
performance out of their systems.
Databases matter, and if you consider yourself a decent software
developer, you need to learn how to tame them. Learn the differences
between them. Learn what they are, what makes them tick, and the most
importantly, how to make them tick faster, because writing
applications that are slow is just bad taste.
‘I think I’ve been in the top 5% of my
age cohort all my life in understanding the power of incentives, and
all my life I’ve underestimated it. And never a year passes but I get
some surprise that pushes my limit a little farther.’